apiVersion: foods/v1tasty
kind: bacon
metadata:
name: breakfast
spec:
thickness: chunky
If you’re a software engineer, there’s a good chance that you might have edited some YAML today. That’s pretty cool, because you can do some rad stuff with YAML these days! You can configure Kubernetes clusters, wrangle servers with Ansible cookbooks, or even automate your home with Home Assistant. In my opinion, YAML is a pretty good language for managing simple data structures, but things can sometimes get a bit frustrating when trying to edit more complex files.
Like me, I imagine that you might have run into a syntax error or two while editing YAML in your past. Even so, I often find myself full of undue hubris when editing YAML:
Me, working on the the last 90% of some feature: Rad, all I need to do is add that port number as an environment variable. That sounds easy!
Me: Cracks open the GitHub web editor and quickly adds the port number without quotes, unconsciously forgetting that YAML will helpfully attempt to cast unquoted values and that
EnvVar.valuerequires astring.Jenkins: Ur code looks great. Ship it! I skipped all of this YAML stuff. What’s that about?
Me: Cool! CI is green and my code has been reviewed! Imma deploy my PR!
Kubernetes: You’ve got yourself a YAMBURGER! See, environment variables are strings but what you provided was an integer.
Me: …
I can’t help but feel like YAML is right smack dab in the uncanny valley of configuration languages. It seems easy enough that many edit it without the help of editor tools that assist us along the way by highlighting errors with squiggly red lines and feel duped when it turns out to be less magical than expected. And because it’s so easy, many software projects lack continuous integration processes for YAML and implicitly expect the author to validate it themselves. That’s a bit of a catch 22, isn’t it?
Complicating things further, simple mistakes in YAML files can often have a pretty large blast radius. I’ll never forget the time I shadowed a YAML hash key in a Hiera file and had to rush to revert a PR to avoid taking down a critical service. That day changed the way I think about YAML - or any configuration language to be honest! The fact that a language isn’t turing complete doesn’t protect you from harm in the event of a typo.
If you’re using YAML to configure a service that you’re responsible for, you owe it to yourself and your service’s users to validate the YAML configuring that service with just as much rigor as you test your code. At the very least, please consider testing that the YAML in your repository is well-formed using continuous integration.
It may delight you, dear reader, to learn that this post contains strategies for doing just that.
Validating YAML
If you’re pushing YAML of any kind to GitHub, you should check out YAMBURGER. It’s a GitHub App that validates the syntax of the YAML files that have been changed on your GitHub Pull Requests, highlighting any YAMBURGERS it finds using the super cool new GitHub Checks feature:
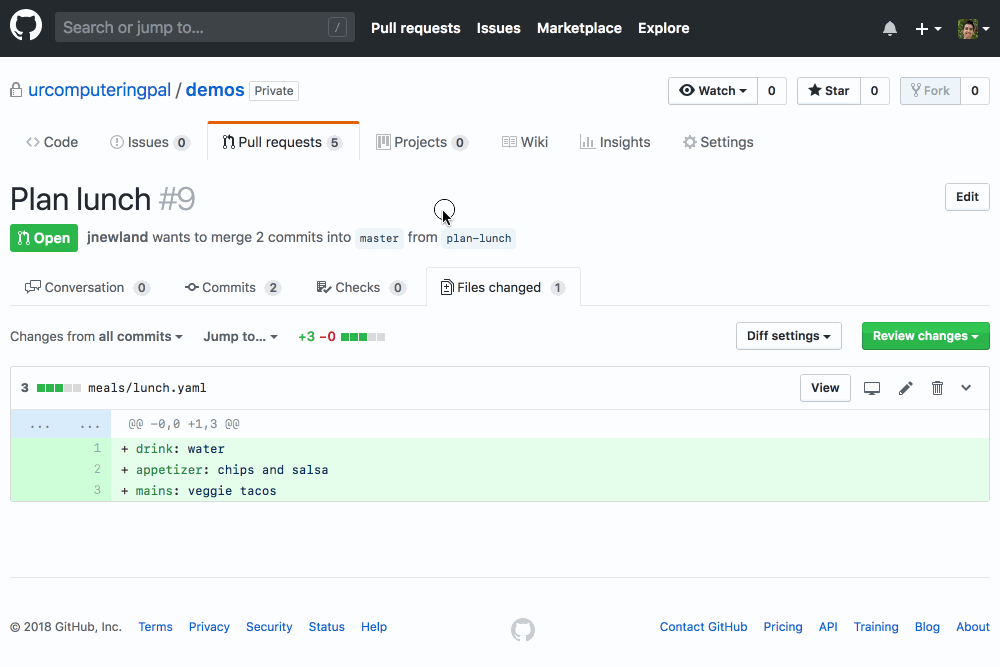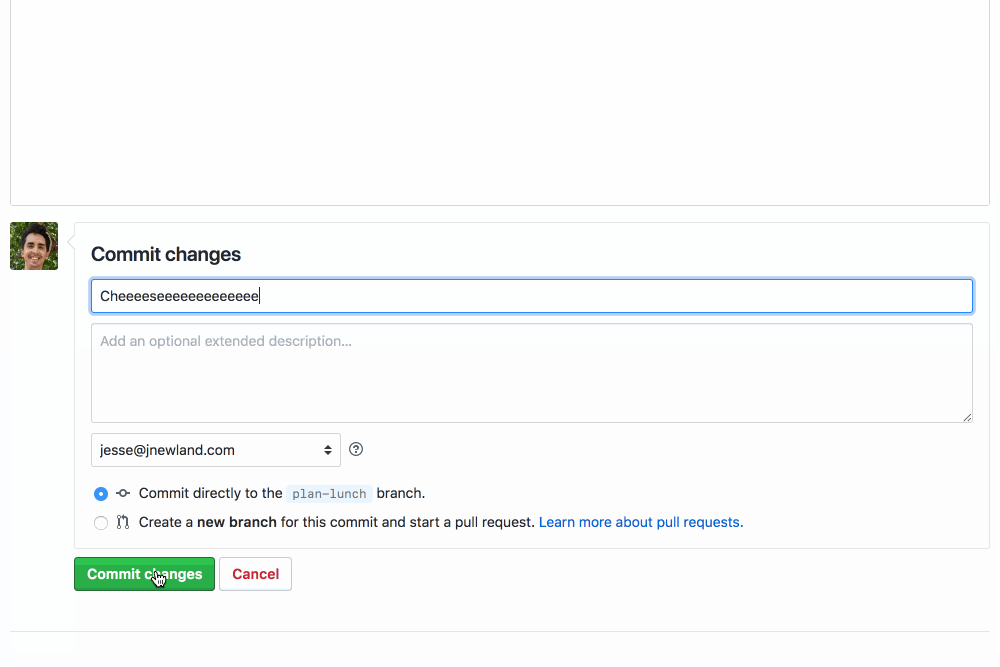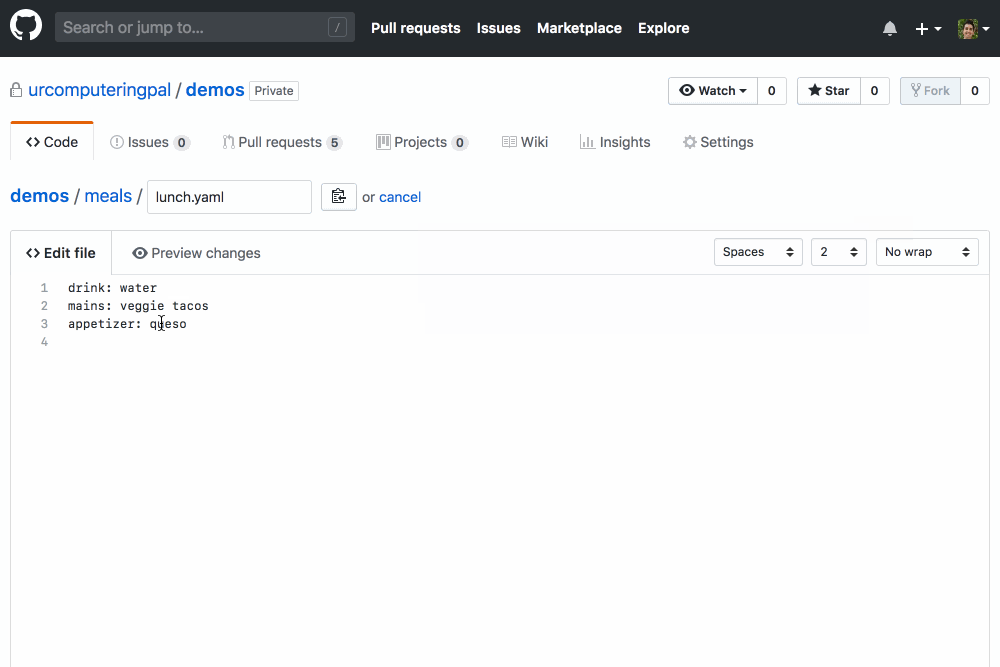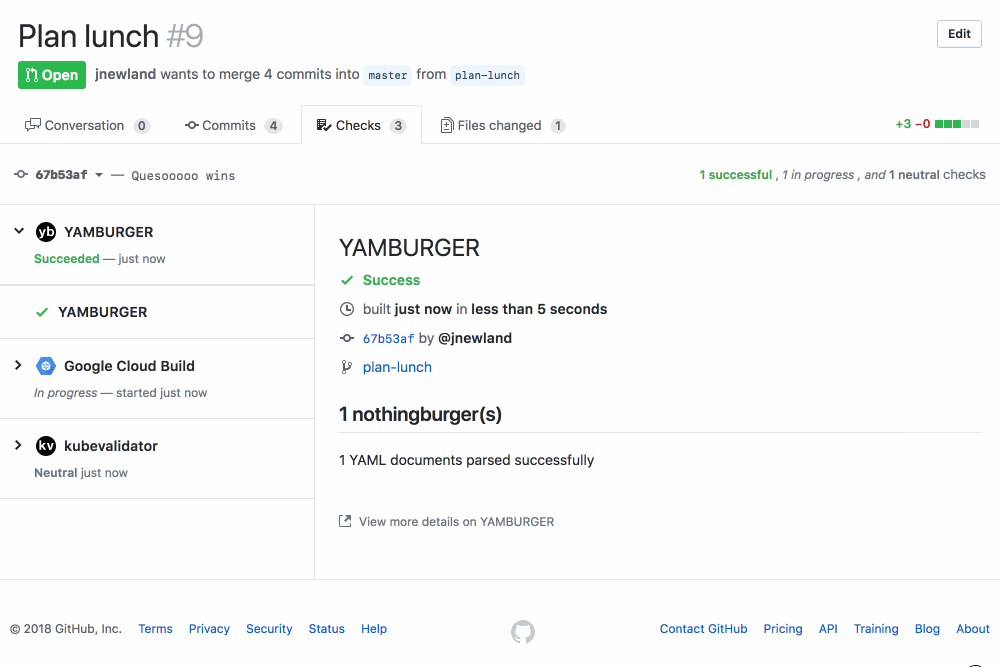
It’s easy to get started: you can install YAMBURGER on your GitHub repositories with a couple clicks. YAMBURGER’s hosted version is free during a limited preview period. The code is open source, so you can run your own deployment on a platform like Heroku or Zeit if you’d prefer! Please reach out if you have any questions, feedback, or feature requests. We’d also be thrilled to accept contributions from anyone willing to adhere to our code of conduct!
Kubernetes YAML
One of my favorite charactaristics of Kubernetes is its opinionated use of declarative configuration. Using kubectl and YAML, an ambitious engineer can describe the infrastructure required to run their service using a handful of YAML files piped to kubectl apply. Quite a few people use this approach:
So I estimate there are about ~420,000 Kubernetes YAML files publicly available on GitHub.
— Gareth Rushgrove (@garethr) August 2, 2018
What have we done?
That’s a lot of YAML! There are many approaches to configuring Kubernetes that don’t require YAML! But the suite of tools supporting this approach continues to expand: tools like Skaffold and Kustomize layer additional functionality on top of your existing kubectl workflow. YAML is certainly a foundational part of the experience of interacting with Kubernetes today, and that seems destined to continue for at least some time.
We didn't expect, long term, that people would still be writing flat explicit yaml files. But here we are. I'm hoping we can move past it but in some ways there are too many choices and so that makes it more complicated.
— Joe Beda (@jbeda) May 18, 2018
As you may have experienced, the complex schemas of many Kubernetes resources highlight YAML’s uncanny-valley-like characteristics. Modern editor tools can help significantly, but they’re not available for everyone’s favorite editor just yet.
Enter kubevalidator
kubevalidator is a GitHub App that validates the contents of the Kubernetes YAML changed on any Pull Request against a set of community-maintained schemas. This essentially enables automatic code review for mistakes that I make all of the time, like these:
- Mis-remembering the name of a field
- Adding a field at the wrong indentation level
- NotSnakeCaseingCorrectly
- Setting environment variables to integers
There are a bunch of other configurable features, like the ability to validate Kubernetes YAML against multiple schema versions. This has turned out to be really helpful during the process of migrating services between clusters or in advance of cluster upgrades! If the default schemas aren’t right for you, kubevalidator makes it easy to use your own: you can validate against a different schema by forking garethr/kubernetes-json-schema and dropping your forkUsername into .github/kubevalidator.yaml.
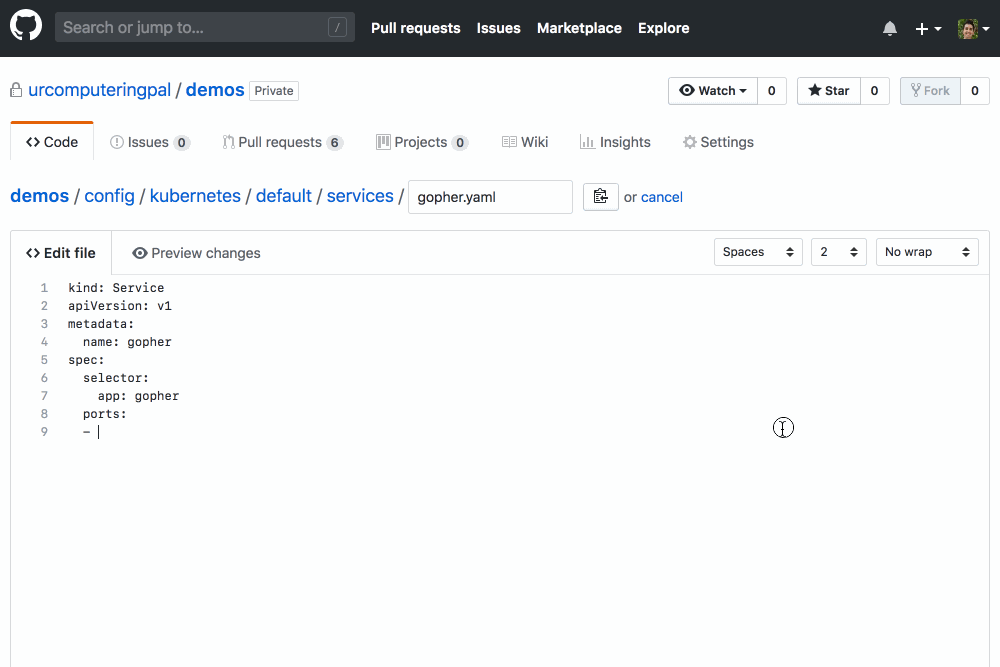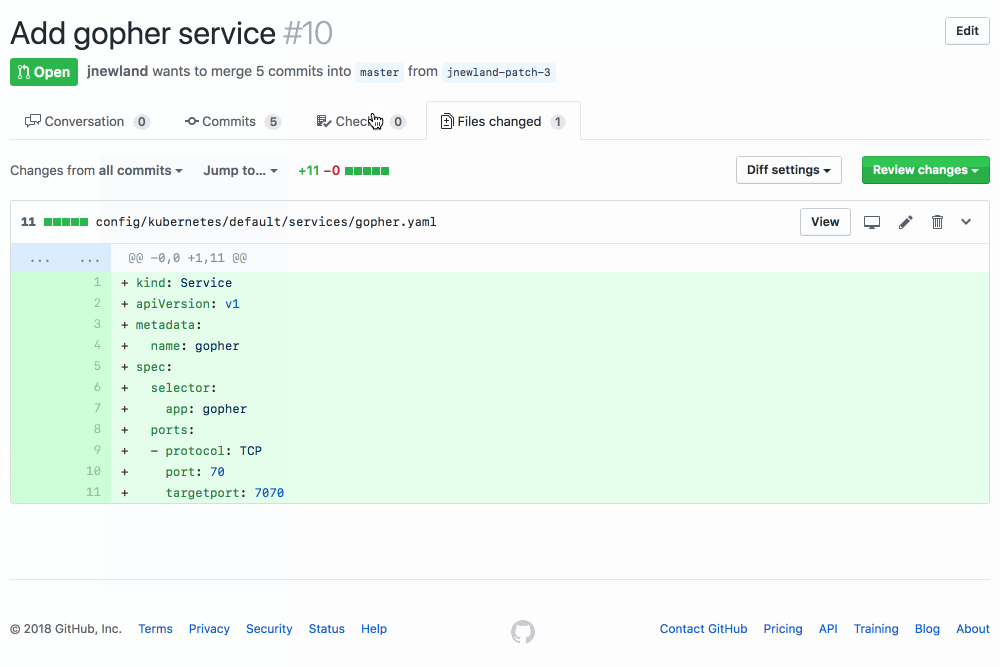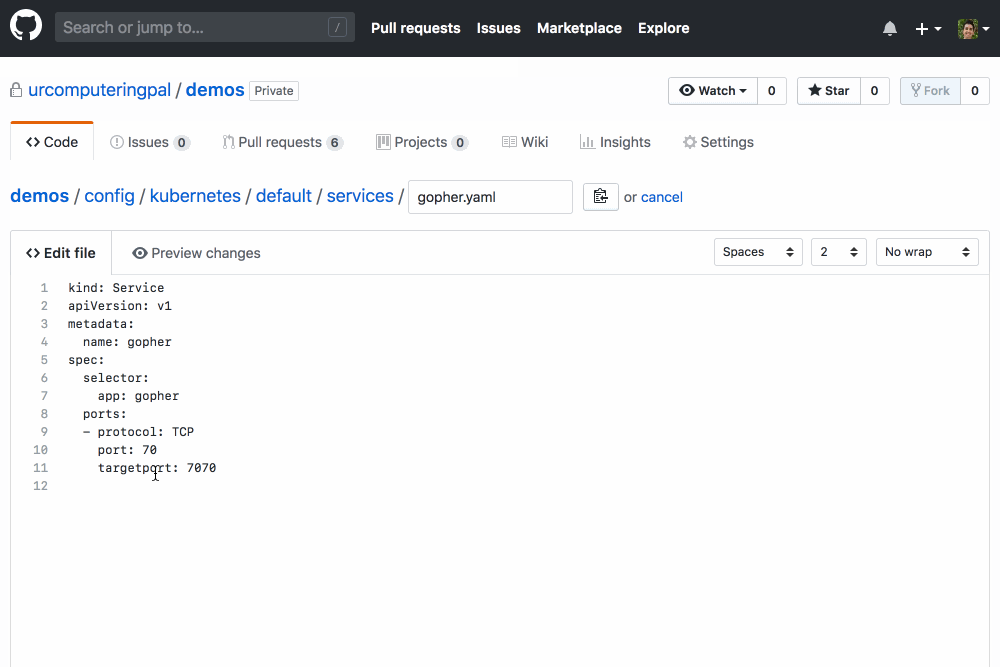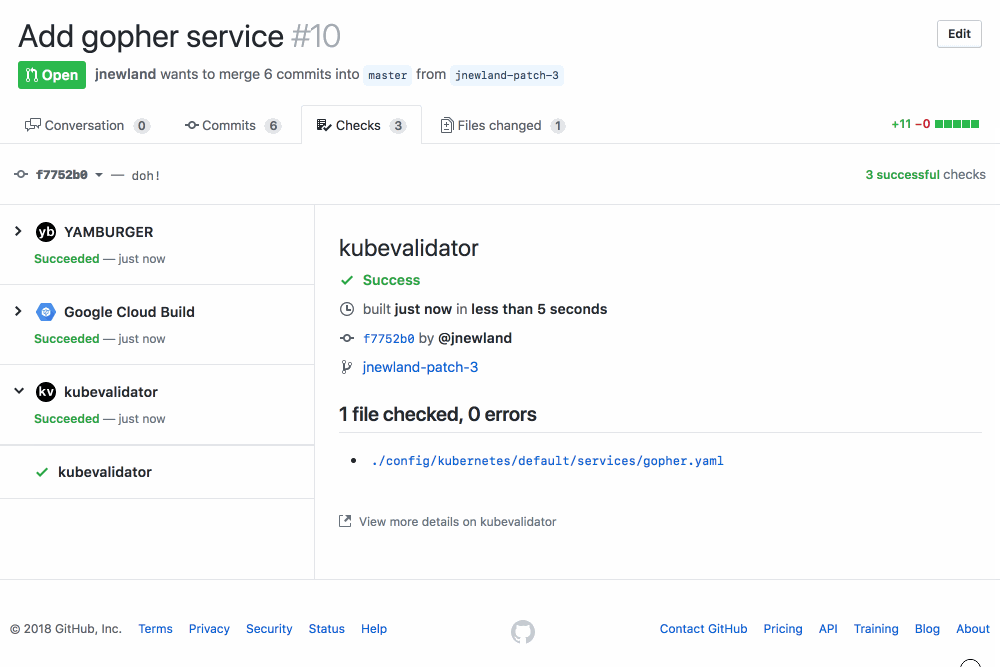
It’s super easy to get started with kubevalidator: install it on your GitHub repositories today and it’ll help you through the process of configuring it. Like YAMBURGER, kubevalidator’s hosted version is free during a limited preview period, but the project is open source along with reference Kubernetes configuration if you’d like to run your own instance.
If you push Kubernetes YAML to GitHub for either fun or profit, install it on one of your GitHub Repositories out today and reach out if you have any questions, feedback, or feature requests! We’d also be thrilled to accept contributions from anyone willing to adhere to our code of conduct.
Acknowledgements
-
 to @keavy, @kytrinyx, @lizzhale and many more for your work on GitHub Checks. PRs aren’t ever going to be the same.
to @keavy, @kytrinyx, @lizzhale and many more for your work on GitHub Checks. PRs aren’t ever going to be the same. -
to @garethr for your work on kubeval. It does all of the heavy lifting for kubevalidator, I’ve just put some GitHub-flavored window dressing on top.
-
to @bkeepers for your work on Probot. I’ve learned a ton building Probot apps in the past few months and hope that you don’t mind that I’ve poorly re-implemented a small portion of it in Golang as a part of kubevalidator.

-
to @broccolini who made the super dope Swiss Jekyll theme this blog uses.
-
to @lindvall for you the review, feedback, and dog photos. Never stop with the dog photos.

-
to @katienewland for being
 in general.
in general.